When the market sells off, it is important to have some dividend stocks in your portfolio. You may want to be overweight on some sectors because of how they react to volatility. When the market reverses, you may be able to sell them at a profit since you already bought those stocks when the market was down. If the bear market continues and you hold them, you will earn dividends. If you are on the Dividend Reinvestment Plan (DRIP), your dividends are automatically reinvested in the underlying equity, i.e. instead of receiving the dividends in a form of cash, your exchange will buy shares using the dividends that you earned.
But how do you choose which dividend stocks, ETFs or mutual funds to buy? You don’t want to chase buying the stocks because of the high dividend yields alone. Some companies pay high dividends but they may later on cut paying dividends because they need cash flow. High quality stocks do not need cash flow in order to pay their stockholders’ dividends.
You may also want to add in your criteria which ones have performed very well in the past. In this tutorial, I check the stocks’ performance and compare them against any benchmark (SPY, QQQ, DJI). They should outperform the benchmark on based these Key Performance Indicators (KPIs):
- Cumulative Annual Growth Rate (CAGR) – is the rate of return (RoR) that would be required for an investment to grow from its beginning balance to its ending balance, assuming the profits were reinvested at the end of each period of the investment’s life span
- Sharpe Ratio – is the average return earned in excess of the risk-free rate per unit of volatility or total risk. Volatility is a measure of the price fluctuations of an asset or portfolio.
- Max Drawdown – is the maximum observed loss from a peak to a trough of a portfolio, before a new peak is attained. Maximum drawdown is an indicator of downside risk over a specified time period.
How do you do all these programmatically? You can create your own Python application from scratch with the help of:
- Fmp Cloud API – Free stock API. As of this writing, you can register for a free API key. There is a limit of 250 API requests/day.
- QuantStats – Python library that provides performance metrics to compute for the KPIs.
This tutorial will cover how to implement a screen like below and the results screen that follows.
Sample screen to enter your search criteria:

Sample output screen:

- PART 1 Get Free API Key from FMP Cloud
- PART 2 Setup Environment Variable
- PART 3 Setup Python project workspace
- PART 4 Writing the code
- PART 5 Running the code
PART 1 FMP CLOUD
Step 1. Go to https://fmpcloud.io and click on GET FREE API KEY button. As of writing, FMP offers 250 requests per day. You may access a maximum limit 5 for all endpoints. The endpoints return only annual data.

Step 2. Sign up by entering your email address and password. You will receive an email for verification. Click the Verify Email Address link from the email.

Step 3. After validating, you may login to your account.

Step 4. Click the Dashboard link on the left panel. Copy the API key. This will be used in the next step.

PART 2 SETUP ENVIRONMENT VARIABLE
Step 1. If you are using Windows, select Control Panel -> System and Security -> System -> Advanced system settings -> Environment Variables..
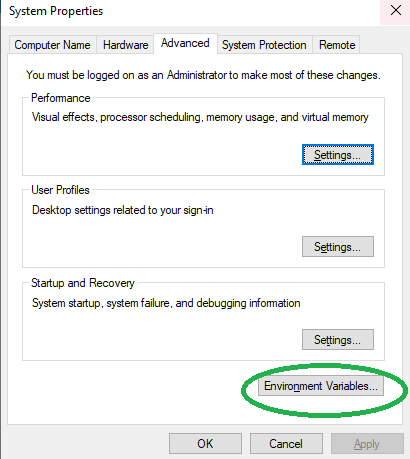
Step 2. Add environment FMPCLOUD_KEY. In the Value field, copy the API Key from PART 1 Step 4. Click OK button.

PART 3 SETUP PYTHON PROJECT WORKSPACE
Step 1. Install Pycharm Community Edition in https://www.jetbrains.com/pycharm/download/
This tutorial uses the latest stable release pycharm-community-2021.1.2.exe
Step 2. Open Pycharm. Create New Project with a Virtual environment. The latest Pycharm installer will always have new virtual environment installed.
Step 3. Create new file with filename requirements.txt
flask
gunicorn
quantstatsStep 4. Select “Terminal” on the bottom panel. This will launch a command line. Execute the command
pip3 install -r requirements.txtPART 4 WRITING THE CODE
Step 4a. Create the HTML for search form. You may download a sample dividendChooserForm.html that I created here. The HTML will have a form tag and action that corresponds to a handler that will later be defined in app.py
<form action="/search" method="POST">
Step 4b. Create a new Python file called app.py . Add lines for libraries and global variables to be used.
from flask import Flask, request, render_template
from typing import Dict, Any
from datetime import datetime
import urllib.request, urllib.response
import json
import quantstats as qs
import os
app = Flask(__name__)
params: dict[Any, Any] = {}
sectors = [{"basicMaterials": 'Basic Materials'}, {"communicationServices": 'Communication Services'},
{"consumerCyclical": 'Consumer Cyclical'}, {"consumerDefensive": 'Consumer Defensive'}, {"energy": 'Energy'},
{"industrials": 'Industrials'}, {"realEstate": 'Real Estate'}, {"technology": 'Technology'},
{"utilities": 'Utilities'}]
USexchanges = {'AMEX', 'NASDAQ', 'NYSE'}
Step 4c. Add a route when your local site is accessed at root http://127.0.0.1/ and another route when use clicks on the Search button
@app.route('/')
def welcome():
return render_template("dividendChooserForm.html", title="")
@app.route('/search', methods=['POST'])
def search():
html = ''
return html
Step 4d. Populate the params by getting the values from the submitted search form.
params["stocks"] = request.form.get("stocks")
params["mutualFund"] = request.form.get("mutualFund")
params["etf"] = request.form.get("etf")
for sector in sectors:
params["".join(list(sector.keys()))] = request.form.get("".join(list(sector.keys())))
params["minLastDividend"] = float(request.form.get("minLastDividend"))
params["minDivYield"] = float(request.form.get("minDivYield")) / 100
params["maxDivYield"] = float(request.form.get("maxDivYield")) / 100
if request.form.get("compareBenchmark") == 'on':
compare_benchmark = True
else:
compare_benchmark = False
params["benchmark"] = request.form.get("benchmark")
params["outperformBenchmarkCAGRBy"] = float(request.form.get("cagrBy"))
params["outperformBenchmarkMaxDrawdownBy"] = float(request.form.get("maxDrawdownBy"))
params["outperformBenchmarkSharpeRatioBy"] = float(request.form.get("sharpeRatioBy"))
params["benchmarkYr"] = request.form.get("benchmarkYr")
params["etf"] = request.form.get("etf")
Step 4e. Call Fmp Cloud API to return a list of assets with dividends higher than number entered in the field “Min. Last Year’s Total Dividend (in $)” on the search form.
key = os.environ.get('FMPCLOUD_KEY')
url = f"https://fmpcloud.io/api/v3/stock-screener?&apikey={key}÷ndMoreThan={params['minLastDividend']}"
response = urllib.request.urlopen(url)
assets = json.load(response)
Step 4f. Filter the assets by checking if they are (1) actively trading (2) belong to the selected security type (stock, mutual funds, ETF) (3) if stock or ETF was selected, they should belong to the selected sectors (4) belong to the major US stock exchanges.
for asset in assets:
if isValidSecurity(params, asset):
...
def isValidSecurity(params, asset):
if asset['isActivelyTrading'] is True and params['mutualFund'] == 'on' and asset[
'exchangeShortName'] == 'MUTUAL_FUND':
return True
if asset['isActivelyTrading'] is True and params['etf'] == 'on' and asset['isEtf'] is True and (
asset['exchangeShortName'] in USexchanges):
return True
if asset['isActivelyTrading'] is True and params['stocks'] == 'on' and (
asset['exchangeShortName'] in USexchanges) and asset['isEtf'] is not True:
for sector in sectors:
if params["".join(list(sector.keys()))] == 'on' and asset['sector'] == "".join(list(sector.values())):
return True
return False
Step 4g. The second filter will be by dividend yield. It should be between Min. Dividend Yield % and Max. Dividend Yield %.
if isValidSecurity(params, asset):
price = asset['price']
latest_Annual_Dividend = asset['lastAnnualDividend']
if latest_Annual_Dividend != 0 and price != 0:
dividend_Yield = latest_Annual_Dividend / price
if dividend_Yield >= params['minDivYield'] and dividend_Yield <= params['maxDivYield']:
DivYield[company] = {}
DivYield[company]['Dividend_Yield'] = dividend_Yield
DivYield[company]['latest_Price'] = price
DivYield[company]['latest_Dividend'] = latest_Annual_Dividend
DivYield[company]['companyName'] = asset['companyName']
DivYield[company]['exchange'] = asset['exchange']
DivYield[company]['isEtf'] = asset['isEtf']
DivYield[company]['Dividend_Sector'] = asset['sector']
DivYield[company]['industry'] = asset['industry']
DivYield[company]['price'] = asset['price']
tickers.append(asset['symbol'])
Step 4h. If the BENCHMARK COMPARISON checkbox was selected, compute for the benchmark’s KPIs using Quantstats
if compare_benchmark is True and len(tickers) > 0:
try:
benchmark_symbol = qs.utils.download_returns(params['benchmark'], period=params['benchmarkYr'] + "y")
SHARPE_RATIO_BENCHMARK = round(qs.stats.sharpe(benchmark_symbol) * (1 + (params['outperformBenchmarkCAGRBy'] / 100)), 3)
MAX_DRAWDOWN_BENCHMARK = round(benchmark_symbol.max_drawdown() / (1 + (params['outperformBenchmarkMaxDrawdownBy'] / 100)), 3)
CAGR_BENCHMARK = round(benchmark_symbol.cagr() * (1 + (params['outperformBenchmarkCAGRBy'] / 100)), 3)
except Exception as e:
print(f'Failed getting benchmark data {type(e)}')
passStep 4i. For the third filter, if user selected BENCHMARK COMPARISON, compare the benchmark’s KPIs with the ticker’s KPIs.
for ticker in tickers:
try:
if compare_benchmark is True:
stock = qs.utils.download_returns(ticker, period=params['benchmarkYr'] + "y")
stock_max_drawdown = round(stock.max_drawdown()* 100, 3)
stock_cagr = round(stock.cagr(), 3)
stock_sharpe_ratio = round(qs.stats.sharpe(stock), 3)
if stock_cagr > CAGR_BENCHMARK and stock_sharpe_ratio > SHARPE_RATIO_BENCHMARK and stock_max_drawdown > MAX_DRAWDOWN_BENCHMARK:
result = {'ticker': ticker, 'stock_cagr': stock_cagr, 'price': DivYield[ticker]['price'],
'divY': DivYield[ticker]['Dividend_Yield'],
'stock_sector': DivYield[ticker]['Dividend_Sector'],
'stock_industry': DivYield[ticker]['industry'],
'companyName': DivYield[ticker]['companyName'],
'exchange': DivYield[ticker]['exchange'], 'isEtf': DivYield[ticker]['isEtf'],
'stock_max_drawdown': stock_max_drawdown,
'stock_sharpe_ratio': stock_sharpe_ratio}
results.append(result)
if compare_benchmark is False:
result = {'ticker': ticker, 'price': DivYield[ticker]['price'],
'divY': DivYield[ticker]['Dividend_Yield'],
'stock_sector': DivYield[ticker]['Dividend_Sector'],
'stock_industry': DivYield[ticker]['industry'],
'companyName': DivYield[ticker]['companyName'], 'exchange': DivYield[ticker]['exchange'],
'isEtf': DivYield[ticker]['isEtf']}
results.append(result)
except Exception as e:
print(f'{ticker} Exception {type(e)}')
pass
Step 4j. Build the HTML string to be returned by the search method
ctr = 1
html += "<br><br><b>SEARCH RESULTS</b>"
row_header = "<tr bgcolor='#A9A9A9'><td><b>#</b></td> <td><b>Ticker</b></td> <td><b>Price</b></td> <td><b>Sector</b></td> <td><b>Industry</b></td> <td><b>Company Name</b></td> <td><b>Exchange</b></td> <td><b>EFT ?</b></td> <td><b>Div Yield %</b></td>"
if compare_benchmark is True:
row_header += "<td><b>CAGR</b></td> <td><b>Max Drawdown</b></td> <td><b>Sharpe Ratio</b></td>"
row_header += "</tr>"
if len(results) > 0:
html += f"<br> <table border='1'>{row_header}"
else:
html += "<br>No match results"
for result in results:
html += f"<tr> <td>{ctr}</td><td>{result['ticker']}</td><td>{result['price']}</td> <td>{result['stock_sector']}</td> <td>{result['stock_industry']}</td> <td> {result['companyName']}</td> <td> {result['exchange']} </td> <td> {result['isEtf']} </td> <td> {round(result['divY'] * 100, 4)} </td> "
if compare_benchmark is True:
html += f"<td> {result['stock_cagr']} </td> <td>{result['stock_max_drawdown']} </td> <td> {result['stock_sharpe_ratio']}</td>"
html += "</tr>"
ctr += 1
if (ctr % 20) == 1:
html += row_header
if len(results) > 0:
html += "</table><br><br>"
PART 5 RUNNING THE CODE
Step 1. Select “Terminal” on the bottom panel.
flask runStep 2. Open a browser and enter http://127.0.0.1/
Areas of improvement:
- This tutorial assumes that you are buying from the US market only. If you want to include stocks, mutual funds and ETFs from other markets, remove the codes where USexchanges variable waw used.
- Implement threading. Depending on your search parameters, there can be hundreds or thousands of results. Using multithreading will greatly improve the execution speed.
- If you are on FMP Cloud’s free subscription, you are allowed only 250 API calls in a day. Keep in mind this limit.
- If at some point FMP does not offer free subscription and you do not want to pay for subscription, as an alternative, you may write your codes to retrieve dividends data using Python libraries.
I hope this post helps you create your own application for choosing dividend stocks that have excellent performance. Cheers!
