Duplicate data is any data that is repeated or redundant in a dataset. It is one of the most common Data Quality issues that concerns organizations.
SAP or Systems, Applications, and Products in Data Processing has been one of the leading enterprise resource planning (ERP) software vendor. Its ERP software package called SAP HANA (High-performance ANalytic Appliance) is a multi-model database that stores data in its memory instead of keeping it on a disk. With this in mind, SAP HANA users would also want to find redundant data in their data to improve Data Quality.
This post gives you the SQL query needed to find the duplicate rows within a sample SAP HANA table.
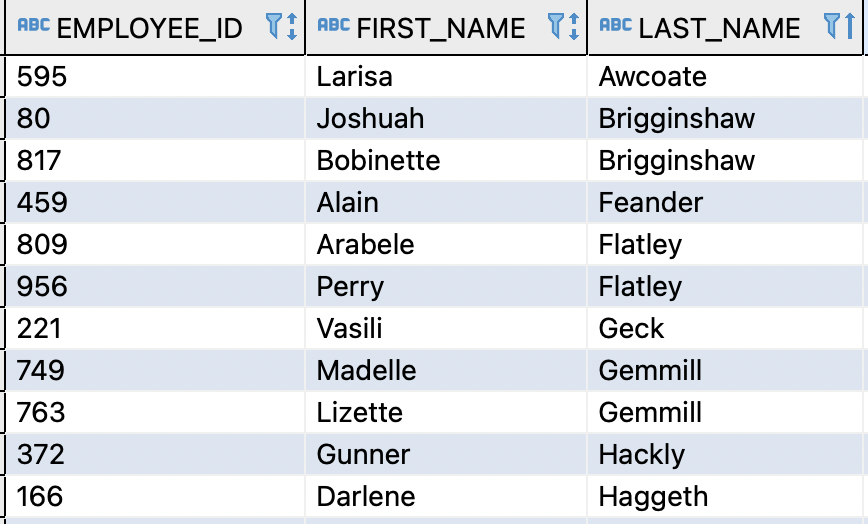
First, let’s create a table with data for example purposes:
CREATE TABLE EMPLOYEES (
EMPLOYEE_ID INTEGER,
FIRST_NAME VARCHAR(100),
LAST_NAME VARCHAR(100))
INSERT INTO EMPLOYEES(EMPLOYEE_ID,FIRST_NAME,LAST_NAME) VALUES (595,'Larisa','Awcoate');
INSERT INTO EMPLOYEES(EMPLOYEE_ID,FIRST_NAME,LAST_NAME) VALUES (80,'Joshuah','Brigginshaw');
INSERT INTO EMPLOYEES(EMPLOYEE_ID,FIRST_NAME,LAST_NAME) VALUES (817,'Bobinette','Brigginshaw');
INSERT INTO EMPLOYEES(EMPLOYEE_ID,FIRST_NAME,LAST_NAME) VALUES (459,'Alain','Feander');
INSERT INTO EMPLOYEES(EMPLOYEE_ID,FIRST_NAME,LAST_NAME) VALUES (809,'Arabele','Flatley');
INSERT INTO EMPLOYEES(EMPLOYEE_ID,FIRST_NAME,LAST_NAME) VALUES (956,'Perry','Flatley');
INSERT INTO EMPLOYEES(EMPLOYEE_ID,FIRST_NAME,LAST_NAME) VALUES (221,'Vasili','Geck');
INSERT INTO EMPLOYEES(EMPLOYEE_ID,FIRST_NAME,LAST_NAME) VALUES (749,'Madelle','Gemmill');
INSERT INTO EMPLOYEES(EMPLOYEE_ID,FIRST_NAME,LAST_NAME) VALUES (763,'Lizette','Gemmill');
INSERT INTO EMPLOYEES(EMPLOYEE_ID,FIRST_NAME,LAST_NAME) VALUES (372,'Gunner','Hackly');
INSERT INTO EMPLOYEES(EMPLOYEE_ID,FIRST_NAME,LAST_NAME) VALUES (166,'Darlene','Haggeth');
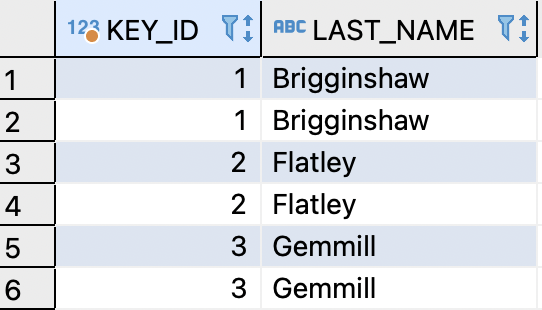
Below is the query that you can use to find exact match duplicate rows of the SAP HANA table created above:SELECT DENSE_RANK() OVER(ORDER BY LAST_NAME) AS key_id,
LAST_NAME
FROM (
SELECT COUNT(*) OVER (PARTITION BY LAST_NAME ORDER BY LAST_NAME) AS cnt,
LAST_NAME
FROM EMPLOYEES)
WHERE cnt > 1
Let’s now dissect the above SQL statement. This inner query returns all LAST_NAMEs and the count for the number of rows that contains the LAST_NAME value.:
SELECT COUNT(*) OVER (PARTITION BY LAST_NAME ORDER BY LAST_NAME) AS cnt,
LAST_NAME
FROM EMPLOYEES
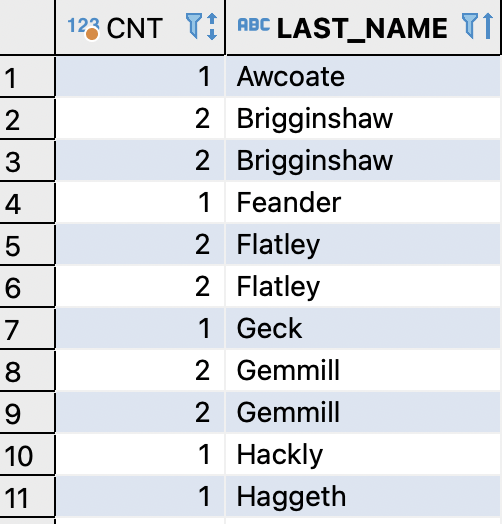
The output of the inner query is then used as the source for the outer query.
Below is the query that you can use to find exact match duplicate rows of the SAP HANA table created above:SELECT DENSE_RANK() OVER(ORDER BY LAST_NAME) AS key_id,
LAST_NAME
FROM (
SELECT COUNT(*) OVER (PARTITION BY LAST_NAME ORDER BY LAST_NAME) AS cnt,
LAST_NAME
FROM EMPLOYEES)
WHERE cnt > 1
DENSE_RANK() returns duplicate values in the rank numbering when there are ties between the LAST_NAME values. Finally we add a filter where we are only interested in ranks whose count is greater than 1.
The final result returns the duplicates with KEY_ID column as the duplicate group’s id and the values of LAST_NAME column